Codage de textes
Python est un langage de haut niveau. Ses concepteurs essaient de le rendre le plus proche possible de l'esprit humain.
Ainsi on peut écrire :
'a' < 'b'
Cela semble logique : dans l'ordre alphabétique, a est bien avant b. On peut donc dire que a est "inférieur" à b.
Mais dans ce cas que dire de :
'à' < 'b'
Dans l'ordre alphabétique, cela ne colle pas... Comment Python compare-t-il les caractères ?
Et surtout comment les caractères et les textes sont-ils codés dans l'ordinateur ?
Quelle suite de $0$ et de $1$ permet de coder les caractères a, b et à?
I. Le code ASCII :¶
Au début de l'informatique, de nombreuses façon de coder les caractères existaient.
Si l'on achetait deux machines de fabriquants différents il était probable que leurs façons de coder les textes soient différente...
Au début des années $1960$, l'Organisation Internationale de Normalisation prend le problème en main.

L'American Standart Association se charge du développement d'une norme ce codage des caractères pour les Etats-Unis.
Cette norme est l'ASCII pour American Standard Code for Information Interchange et est publiée pour la première fois en $1963$. Elle s'impose au niveau international.
En ASCII, chaque caractère est codé sur $8$ bits mais en fait le bit de poids fort n'est jamais utilisé. Un caractère occupe donc $7$ bits ce qui fait $2^7 = 128$ caractères possibles :
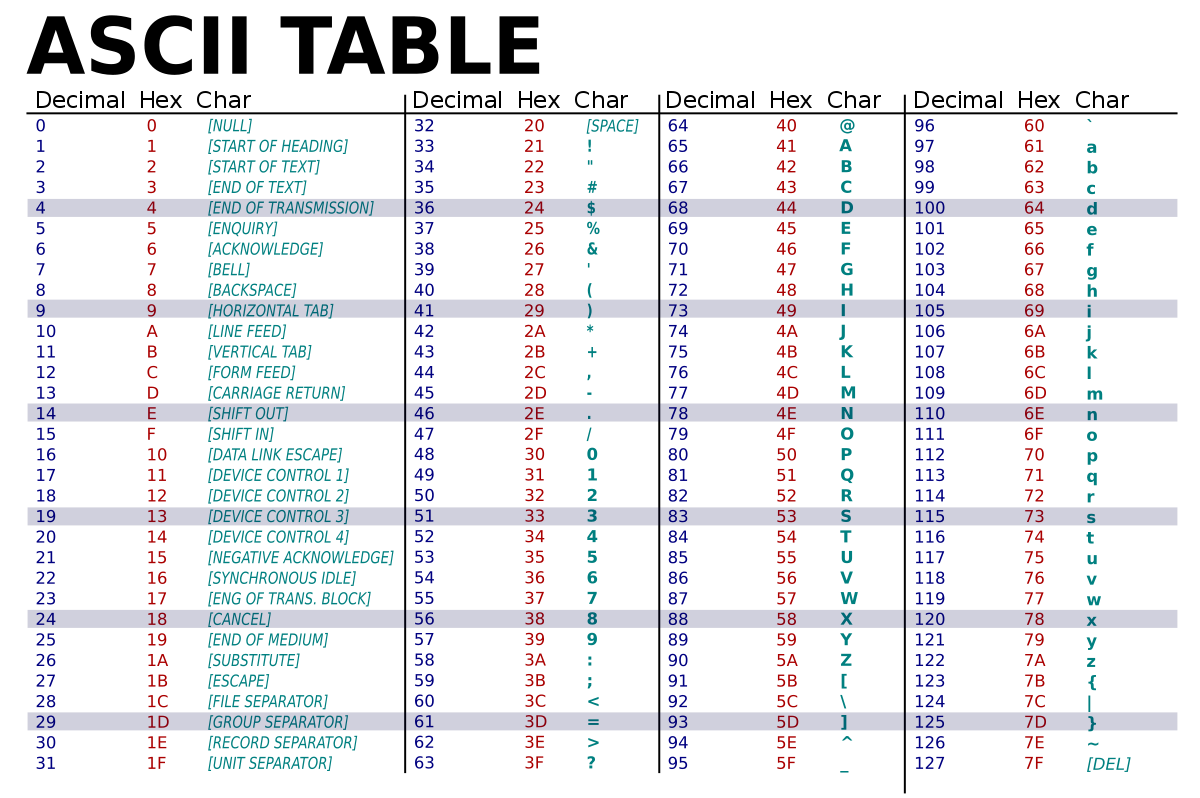
On le voit, à chaque caractère est associé un nombre.
Ainsi, le A est codé par $65$ en décimal ou $41$ en hexadécimal ou $1000001$ en binaire.
Le standart est astucieux : le a est codé par $97$, il est donc $32$ caractères après le A. Leurs codes binaires diffèrent donc peu ($1100001$ pour le a).
Python connaît cette table. Les fonctions ord et chr permettent de passer d'un caractère à son code et réciproquement :
ord('A')
chr(65)
On peut ainsi, très facilement faire du code de César (décalage de la lettre dans l'alphabet) :
cle = 8
texte_clair = "Hello World"
texte_code = ""
for lettre in texte_clair :
numero = ord(lettre)
texte_code += chr(numero + cle)
print(texte_code)
texte_decode = ""
for lettre in texte_code :
numero = ord(lettre)
texte_decode += chr(numero - cle)
print(texte_decode)
L'ASCII a tout de même un (très) gros défaut : il ne code que les caractères américains. Pas d'accents, pas d'idéogrammes chinois, de lettres arabes... Il a donc fallu compléter cela.
II. La norme ISO-8859-1 :¶
Afin de pallier les manques d'ASCII, de nouvelles tables ont été créées.
L'une d'entre elle, la table ISO-8859-1 a été reconnue comme standart pour internet.
Elle complète la table ASCII en utilisant les $8$ bits du codage. On peut donc désomais coder jusqu'à $256$ caractères ce qui est suffisant pour écrire le français (quoique, le œ de œsophage manque à l'appel...)
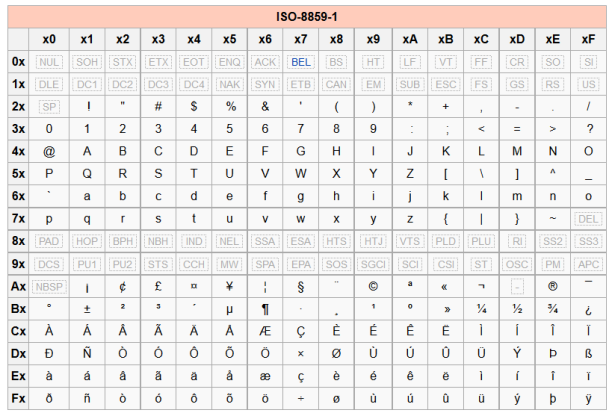
Une étude attentive montre que les $128$ premiers caractères sont les mêmes que dans la table ASCII (retro-compatibilité !).
En fait, Python connaît aussi cette norme :
ord('ÿ')
chr(254)
Cette table permet d'expliquer notre comparaison initiale : on a à > b car leur numéros de caractères sont $e0_{16} = 224_{10}$ et $62_{16} = 98_{10}$.
On a donc de même :
'à' < 'â' < 'ã'
Cette nouvelle table est utilisée pour les textes européens. Elle est même courament appelée latin1 (elle met en forme l'alphabet latin).
Totuefois, on a toujours pas d'idéogrammes, de lettres arabes... Il existe bien des tables adaptées à différentes langues mais aucune commune à toute. Ainsi, si vous échangez avec un camarade en Chine, vous ne pourrez pas utiliser les mêmes tables de caractères...
III. L'Unicode :¶
Cette dernière table vise à pallier les manques des précédentes.

L'Unicode est maintenu par l'Unicode Consortium. Cette table est en fait un répertoire de caractères.
A chaque caractère est associé un code, appelé point unicode.
La version de mars $2019$ de la table compte $137\:928$ caractères ! Elle vient même d'ajouter des émoticônes : 😆 est le caractère U+1F606.
Il serait fastidieux d'afficher ici tous les caractères de l'unicode. Le site https://unicode-table.com/fr/ permet toutefois de les trouver. Pouvez-vous trouver le இ, fameuse lettre tamoule ?
L'unicode est donc un "simple" répertoire. L'encodage des caractères, la façon de les coder en binaire dans l'ordinateur, peut varier. On retient trois standarts :
- UTF-8 : les caractères sont codés sur $8$ bits ($256$ valeurs). Ces $256$ valeurs correspondent globalement à l'ISO-8859-1. Si un caractère "dépasse" la $256$-ième valeur, on utilise un autre octet, voire plusieurs autres. On peut ainsi coder l'ensemble des caractères unicode en utilisant dans la plupart des cas (textes de l'alphabet latin) que peu de données ($8$ bits)
- UTF-16 : même idée mais sur 16 bits. On code par défaut plus de caractères mais on prend plus de place...
- UTF-32 : idem en 32 bits. Pas besoin d'ajouter de nouveaux caractères, tous y sont déjà par défaut
Python connaît aussi l'unicode :
# Affiche un caractère unicode indiqué par son code
print(u'\u0B87')
# Donne l'encodage utf-8 en hexadécimal du code unicode
print('UTF-8', u'\u0B87'.encode('utf-8'))
# Vérifier avec : https://unicode-table.com/fr/0B87/