Les requêtes HTTP
Le protocole HTTP, pour HyperText Transfer Protocol, a été inventé au début des années 1990 par Tim Berners-Lee avec les adresses Web et le langage HTML pour créer le World Wide Web.
Ce protocole est celui qu'utilise notre navigateur afin de communiquer avec un poste distant, le plus souvent un serveur.
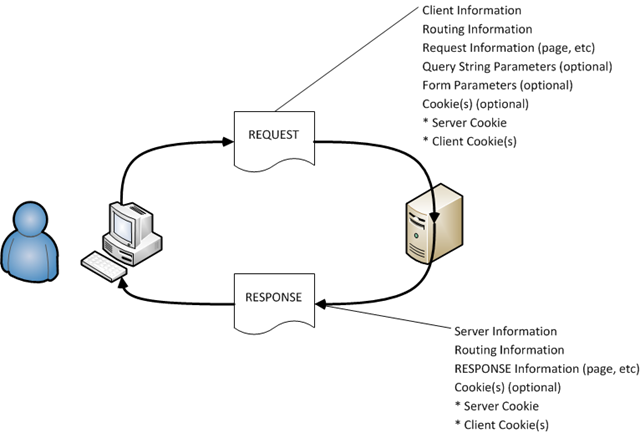
Comme le montre la figure ci-dessus, le client émet des requêtes et le serveur envoie en retour des réponses.
Il existe plusieurs types de requêtes, ou méthodes. Voici les principales pour nous :
GETMéthode la plus courante pour demander une ressource. Une requête GET est sans effet sur la ressource (elle ne la modifie pas). Il est possible de passer des paramètres supplémentaires en les ajoutant à la fin de l'adresse URL
HEADDemande des informations sur la ressource, sans demander la ressource elle-même
POSTCette méthode est utilisée pour transmettre des données en vue d'un traitement à une ressource (le plus souvent depuis un formulaire HTML). On l'envoie à une ressources (une page web) qui traitera les données. Le résultat peut être la création de nouvelles ressources ou la modification de ressources existantes
I. La requête GET :¶
Ouvrons un navigateur et l'outil de débuggage ("Examiner l'élément" ou F12 sur Firefox). Sélectionnons l'onglet "Réseau".
Une fois dans cet outil, chargeons une page web. Par exemple DuckDuckGo !. On obtient des informations de ce type :

Comme on peut le voir tout en bas, notre navigateur a envoyé plusieurs requêtes (21 ici).
Dans cet exemple, il ne s'agit que de requêtes GET.
La première d'entre elles demandait la ressource https://duckduckgo.com/ auprès de l'IP 46.51.179.90 et du port 443 (un genre de porte ouverte sur le poste distant).
A cette réponse, le serveur a répondu positiviment (d'où le code 200) et transmis la ressources (le code html en l'occurence).
Après réception, le navigateur du client a réalisé qu'il avait besoin d'autres ressources afin d'afficher correctement la page : les images, le code CSS...
Il a donc effectué 20 requêtes GET supplémentaires.
Voici le code de la première requête côté client/navigateur donc :
GET / HTTP/1.1
Host: www.duckduckgo.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate, br
DNT: 1
Connection: keep-alive
Upgrade-Insecure-Requests: 1On y trouve :
- le type de requête (GET), un slash (
/) et la version de HTTP utilisée. Le/indique que l'on souhaite charger la ressource par défaut du domaine (le plus souvent le fichierindex.html) - le nom de l'hôte (le domaine) hébergeant la ressource
- des informations sur notre navigateur et notre système d'exploitation (Firefox/68.0, Windows 10)
- le type de données acceptées
- les langues acceptées
- les encodages acceptés
- un indicateur DNT pour Do Not Track à 1 donc
Trueindiquant que l'on ne souhaite pas être pisté pour des publicités - ...
Le serveur a répondu avec le code 200, indiquant que tout s'est bien passé. Voici quelques autres codes possibles :
100, ContinueAttente de la suite de la requête
200, OKRequête traitée avec succès. La réponse dépendra de la méthode de requête utilisée
301, Moved PermanentlyDocument déplacé de façon permanente
A partir de 400 on ne trouve que des statuts d'erreur.
400, Bad RequestLa syntaxe de la requête est erronée
401, UnauthorizedUne authentification est nécessaire pour accéder à la ressource
403, ForbiddenLe serveur a compris la requête, mais refuse de l'exécuter. Il est peut-être nécessaire de s'authentitifer et surtout d'avoir des droits d'accès à cette ressource
404, Not FoundLa fameuse erreur 404 : la ressource n'a pas été trouvée
Faisons désormais une recherche sur notre moteur de recherche.
Par exemple si l'on effectue une recherche sur le "protocole http", on observe que la première requête est la suivante :
GET https://duckduckgo.com/?q=protocole+http&t=h_&ia=web HTTP/1.1L'adresse classique du site s'est vue augmentée de différents paramètres :
?q=protocole+http&t=h_&ia=webCes sont des ajouts à la requête, en anglais query. On voit qu'ils contiennent entre autre notre recherche.
Ici il y a trois variables passées :
qqui vautprotocole+httptqui vauth_iaqui vautweb
Comme les informations sont transimes dans l'URL de la resource demandée, cette façon de passer des informations n'est pas du tout sécurisée. Ce serait une très mauvais idée de procéder ainsi pour transmettre un mot de passe !
II. La requête POST :¶
Comment transmettre des informations de façon sécurisée donc ? Une méthode basique consiste à utiliser une requêtre POST.
C'est cette méthode que l'on va utiliser dans des formulaires sur internet.
Voici un formulaire basique :
Login : <input type="text" name="login" />
Mot de passe : <input type="password" name="mdp" />
<input type="submit" value="Valider" />
</form>
Ce qui donne :
Il s'agit de transmettre un identifiant de connexion ainsi qu'un mot de passe.
Les données seront transmises lorsque l'on cliquera sur le bouton (type="Submit") et la transmission se fera avec une requête POST (methode="post").
A quoi ressemble cette méthode POST ?
POST identification.php HTTP/1.1
Host: monDomaine.com
login="toto"&mdp="azerty"On trouve bien:
la page demandée
identification.php. C'est elle qui se chargera du traitement des donnéesle nom de domaine
les noms des variables et leurs valeurs. Ici notre utilisateur
totoa un très mauvais mot de passe !
Ces informations sont passées dans le code de la requête. C'est plus sécurisé que dans l'URL.
Remarque : le mieux est tout de même d'utiliser le protocole HTTPS ou le S implique de la sécurité (autehntification du serveur par un site de confiance et chiffrement de tous les échanges)
Que va-t-il se passer côté serveur ? On a demandé une ressource au format PHP (identification.php).
Le serveur va donc éxécuter du code PHP afin de tester la validité des informations. Il récupérera les données POSTées en faisant $_POST['login'] et $_POST['mdp'].
Voir le cours sur l'interactivité pour quelques détails supplémentaires.
En bilan, voici un tableau présentatnt les différences entre les requêtes GET et POST :
| Type | GET | POST |
|---|---|---|
| Stocké dans l'historique | Oui (avec l'URL) | Non |
| Marque-Page | Oui | Non |
| Bouton Retour | La requête est renvoyée mais les données ne sont pas forcément rechargées car déjà stockées dans le cache du navigateur | Le navigateur avertit que des données vont être renvoyées |
| Paramètres | Envoyés dans l'URL donc pas de tous les types possibles | Envoyés dans la requête. Tous les types possibles (y compris des fichiers) |
| Sécurité | Peu sécurisée car les paramètres sont envoyés dans l'URL et stockés avec celle-ci côté client et serveur | Plus sécurisée car les paramètres sont envoyés dans la requête et non stockés |
| Taile | La taille d'une URL est limitée (2048 caractères) donc une requête GET aussi | Pas de restrictions |
| Visibilité | Une requête GET est visible par quiconque voit l'URL (en physique ou sur le réseau) | La requête POST n'est pas visible dans l'URL |
| Mémoire Cache | Peut être sauvée dans la mémoire cache du navigateur | N'est pas sauvée dans la mémoire cache |