Tri par insertion et par sélection
On considère dans ce cours le tri d'un tableau de valeurs. Celles-ci peuvent être de types différents :
- nombres
- chaînes de caractères
- ...
On considérera ici le cas de nombres entiers.
from random import shuffle
def melange_tableau(taille) :
"""
Création d'un tableau mélangé d'entiers entre 0 et taille - 1
Prend en entrée la taille du tableau (entier >= 1)
Renvoie le tableau mélangé
"""
# Génération du tableau non mélangé
tableau = list(range(taille))
# Mélange du tableau
shuffle(tableau)
return tableau
tableau = melange_tableau(100)
print(tableau)
On obtient ainsi un tableau contenant les entiers entre $0$ et $99$ qu'il va s'agir de trier dans l'ordre croissant.
On pourra compléter la lecture de ce cours par la visite de différents sites internet :
I. Tri par sélection :¶
I.1. Présentation :¶
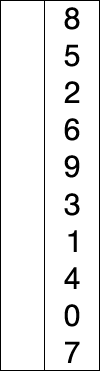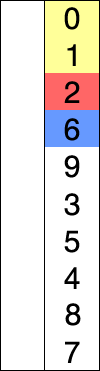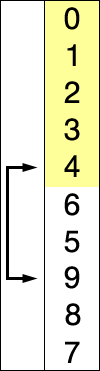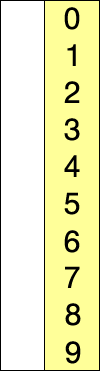
C'est le tri du joueur de carte : à chaque étape on parcourt l'ensemble des cartes restant à trier pour trouver la plus petite et onla place au début de la liste.
Le pseudo-code est le suivant :
tableauest le tableau des valeurs à trierPour
iallant de0jusqu'àlongueur du tableau - 2:indice_minprend la valeuriPour
jallant dei+1jusqu'àlongueur du tableau - 1:Si
tableau[j] < tableau[indice_min]:indice_minprend la valeurj
Echanger les valeurs
tableau[i]ettableau[indice_min]

En python :
def tri_selection(tab) :
"""
Tri le tableau d'entiers tab par sélection
Renvoie le tableau trié
"""
for i in range(len(tab)-1) :
indice_min = i
for j in range(i+1, len(tab)) :
if tab[j] < tab[indice_min] :
indice_min = j
tab[i], tab[indice_min] = tab[indice_min], tab[i]
return tab
tableau = melange_tableau(100)
print(tableau)
print(tri_selection(tableau))
I.2. Caractéristiques :¶
Il s'agit d'un tri en place : les éléments sont triés directement dans le tableau initial.
Ce n'est pas un tri stable : si deux éléments étaient égaux, celui apparaissant initialement en premier dans le tableau porrait ressortir en second à l'issue du tri.
Est-on sûr que cet algorithme s'arrête ? On peut choisir comme invariant de boucle la proposition suivante :
$$Au \: i-ème \: tour \: de \: boucle \:, les \: éléments \: de \: 0 \: à \: i-1 \: sont \: triés$$Cette propriété est toujours vraie :
- Initialisation :
- au $1er$ tour le boucle, l'élément d'indice $0$ est trié (c'est le seul)
- Hérédité :
- on suppose que l'on a atteint la $i-ème$ boucle et donc que les éléments d'indices $0$ à $i-1$ sont triés
- au $(i+1)-ème$ tour de boucle, on trouve le plus petit élément entre $i$ et la fin du tableau et on le place à l'indice $i$. Les éléments d'indices $0$ à $i$ sont donc bien triés
Qu'en est-il de la complexité ? On note $n$ la taille du tableau.
- Au premier tour de boucle le programme doit lire et comparer tous les nombres d'indices entre $0$ et $n-1$. Cela fait $n$ comparaisons
Au deuxième tour de boucle le programme doit lire et comparer tous les nombres d'indices entre $1$ et $n-1$. Cela fait $n-1$ comparaisons
Au troisième tour de boucle le programme doit lire et comparer tous les nombres d'indices entre $2$ et $n-1$. Cela fait $n-2$ comparaisons
...
Au dernier tour de boucle le programme doit lire et comparer tous les nombres d'indices entre $n-1$ et $n-1$. Cela fait $1$ comparaison
Il y a donc en tout : $$(n-1) + (n-2) + (n-3) + \dots + 2 + 1$$ comparaisons.
Une formule de mathématiques montre que cette somme vaut $\frac{n(n-1)}{2} = \frac{1}{2}n^2-\frac{1}{2}n$
On voit que le terme dominant est $n^2$ : cet algorithme est de complexité quadratique $\mathcal{O}(n^2)$
Cela implique que si l'on multiplie la taile des données par $10$, le nombre d'opération et donc temps d'éxécution seront multiplié par un facteur $10^2=100$ :
# Tableau de taille 100
tableau = melange_tableau(100)
%timeit tri_selection(tableau)
# Tableau de taille 1000
tableau = melange_tableau(1000)
%timeit tri_selection(tableau)
# Tableau de taille 10 000
tableau = melange_tableau(10_000)
%timeit tri_selection(tableau)
II. Tri par insertion :¶
II.1. Présentation :¶
La démarche est assez classique : à chaque étape on sort une valeur et on la place à sa position dans la partie gauche de la liste. On passe ensuite à la valeur suivante.
Le pseudo-code est le suivant :
tableauest le tableau des valeurs à trierPour
iallant de0jusqu'àlongueur du tableau - 1:Pour
jallant deijusqu'à1(à rebours):Si
tableau[j-1] > tableau[j]:- Echanger les valeurs
tableau[j-1]ettableau[j]
- Echanger les valeurs
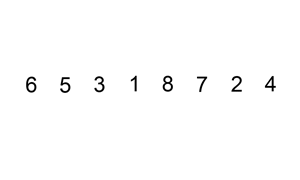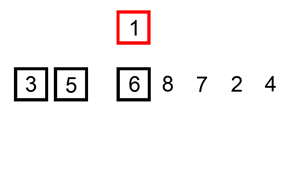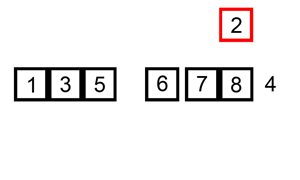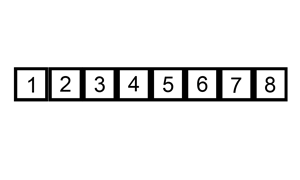

En python :
def tri_insertion(tab) :
"""
Tri le tableau d'entiers tab par insertion
Renvoie le tableau trié
"""
for i in range(len(tab)) :
for j in range(i, 0, -1) :
if tab[j-1] > tab[j] :
tab[j-1], tab[j] = tab[j], tab[j-1]
return tab
tableau = melange_tableau(100)
print(tableau)
print(tri_insertion(tableau))
II.2. Caractéristiques :¶
Il s'agit d'un tri en place : les éléments sont triés directement dans le tableau initial
C'est pas un tri stable : si deux éléments sont égaux, ils ne changent pas de place à l'issue du tri
Est-on sûr que cet algorithme s'arrête ? On peut choisir comme invariant de boucle la proposition suivante :
$$Au \: i-ème \: tour \: de \: boucle \:, les \: éléments \: de \: 0 \: à \: i-1 \: sont \: triés$$Cette propriété est toujours vraie :
- Initialisation :
- au $1er$ tour le boucle, l'élément d'indice $0$ est trié (c'est le seul)
- Hérédité :
- on suppose que l'on a atteint la $i-ème$ boucle et donc que les éléments d'indices $0$ à $i-1$ sont triés
- au $(i+1)-ème$ tour de boucle, on insère le $i-ème$ élément à sa position entre la position $0$ et $i$. Les éléments d'indices $0$ à $i$ sont donc bien triés
Qu'en est-il de la complexité ? On note $n$ la taille du tableau. On se place dans le pire des cas : le tableau est initialement trié dans l'ordre décroissant.
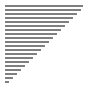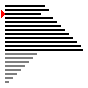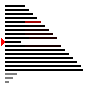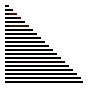
Au premier tour de boucle le programme doit échanger les valeurs d'indices $0$ et $1$. Cela fait $1$ échange (le $0$ à la place du $1$)
Au deuxième tour de boucle le programme doit échanger les valeurs d'indices $0$, $1$ et $2$. Cela fait $2$ échanges (le $2$ à la place du $1$ puis le $1$ à la place du $0$)
Au troisième tour de boucle le programme doit échanger les valeurs d'indices $0$, $1$, $2$ et $3$. Cela fait $3$ échanges (le $3$ à la place du $2$ ...)
...
Au troisième tour de boucle le programme doit échanger les valeurs d'indices $0$, $1$, $2$, ... et $n-1$. Cela fait $n-1$ échanges
Il y a donc en tout : $$1 + 2 + 3 + \dots + (n-1)$$ comparaisons.
Là encore cela donne $\frac{n(n-1)}{2} = \frac{1}{2}n^2-\frac{1}{2}n$
Le terme dominant est toujours $n^2$ : cet algorithme est de complexité quadratique $\mathcal{O}(n^2)$
# Tableau de taille 100
tableau = melange_tableau(100)
%timeit tri_insertion(tableau)
# Tableau de taille 1000
tableau = melange_tableau(1000)
%timeit tri_insertion(tableau)
# Tableau de taille 10 000
tableau = melange_tableau(10_000)
%timeit tri_insertion(tableau)
Il existe de nombreux autres algorithmes de tri, certains, beaucoup plus efficaces que les deux présentés ci-dessus :
