
- Architectures Matérielles -
Processus et Ressources
Aussi rapides et efficaces soient-ils nos ordinateurs ne possèdent que peu d’unités de calculs. Pendant des dizaines d’années, ils ne possédaient à vrai dire qu’un seul processeur et ne pouvaient donc accomplir qu’une seule opération à la fois. L’arrivée récente des ordinateurs multi-coeurs n’a pas changé fondamentalement les choses : nos ordinateurs ne peuvent pas accomplir au même instant toutes les tâches que nous leur demandons.
De façon symétrique, les ressources d’un ordinateur sont limitées : quelques barettes de mémoire vive, un ou deux disques durs, un moniteur… Il faut bien décider quel programme a accès à la ressource à quel instant : si l’on est en train de travailler sur un traitement de texte tout en écoutant de la musique stockée sur le disque dur, comment gérer le moment où l’on sauvegarde son document ?
Le fonctionnement classique organise les tâches de l’ordinateur en processus. Le logiciel chargé de gérer ces processus et de décider lequel s’exécute à quel instant, lequel a accès aux ressources, est le système d’exploitation.
On peut se représenter un processus comme une tâche, comme un programme s’exécutant sur l’ordinateur.
Tant que l’on n’affiche aucune image à l’écran, le programme d’affichage n’est qu’un programme, une suite de \(0\) et de \(1\) dans la mémoire. A l’instant ou l’on double-clique sur une image (ou que l’on l’appelle à partir d’un terminal), ce programme est chargé dans la mémoire-vive et s’exécute : il devient un processus.
Cette vision mérite toutefois d’être précisée :
d’une part, il faut comprendre que tout est processus. Le système d’exploitation qui gère les processus, s’exécute lui-même sous forme de processus
d’autre part, un programme qui s’exécute peut correspondre à plusieurs processus. Le logiciel utilisé pour taper ce document utilise actuellement \(8\) processus différents !
Chaque processus est associé à différentes ressources : des données en mémoire, le numéro de la prochaine instruction à exécuter… Il est identifié par un numéro unique, son Process ID ou PID
Lors du démarrage, l’ordinateur charge un premier processus. Sur les systèmes Linux, il s’agit de init. C’est ce processus qui va démarrer le système d’exploitation et lancer les suivants.
A part ce premier processus, tous les autres sont créés par d’autres processus : chacun est l’enfant d’un processus parent. Cette structure permet de construire un arbre présentant l’ensemble des processus s’exécutant sur l’ordinateur.
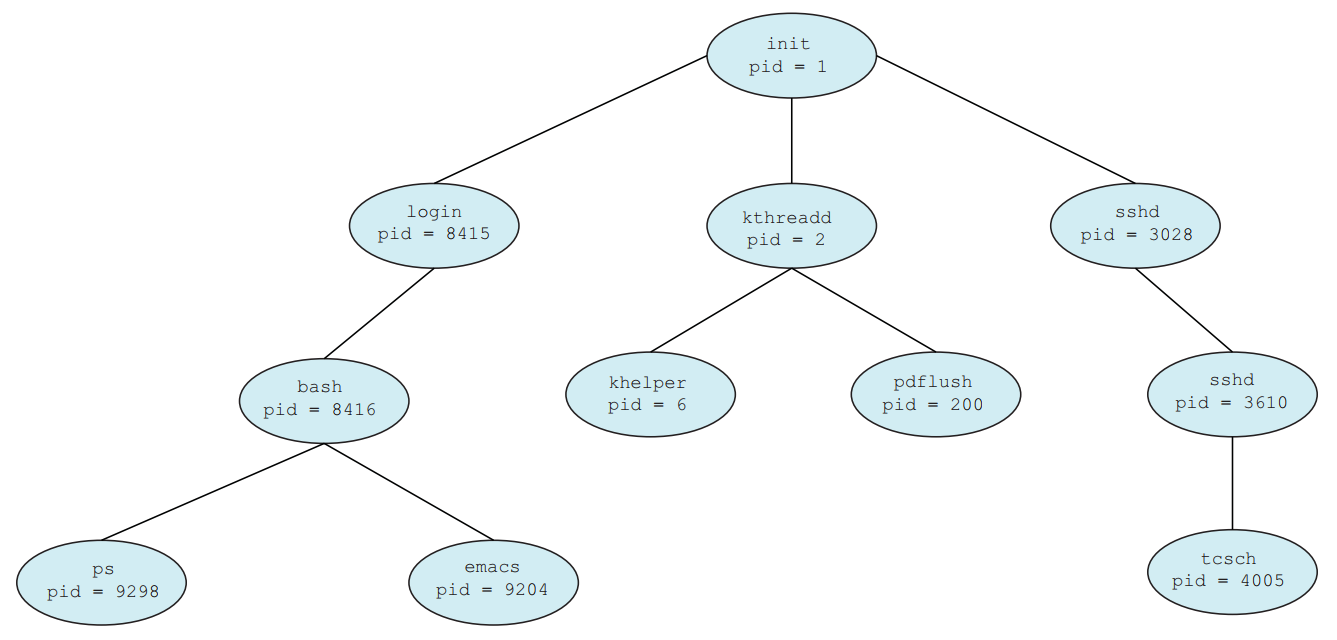
L’arbre de la figure 2 montre ainsi les processus d’un système Linux. On retrouve le processus amorce init. Celui-ci a trois enfants dont login qui gère l’utilisateur actuellement connecté. Celui-ci a manifestement ouvert un terminal (bash) et saisi l’intérieur la commande ps puis ouvert un traitement de texte avec emacs.
Il est facile de lister les processus s’exécutant sur une machine :
ps -el dans un terminalGet-Process dans le powershell
On l’a dit, tous les processus ne s’exécutent pas en même temps. A chaque instant, tous les processus se trouvent dans l’un des trois états suivants :
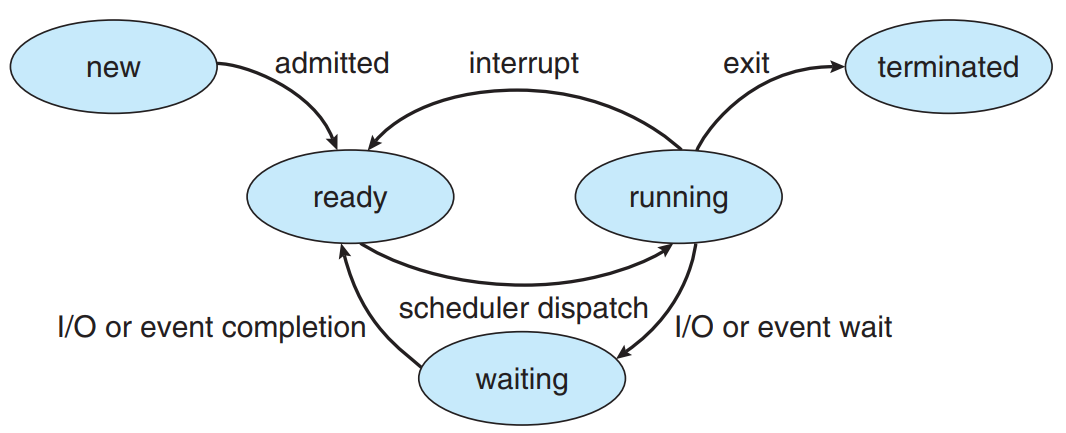
Les processus passent ainsi d’un état à l’autre lors de leur exécution. Afin de rentabiliser la puissance de calcul du processeur, le processus exécuté peut alors changer d’un instant à l’autre si par exemple :
Le choix du processus auquel donner la main est fait par le système d’exploitation. Le choix peut s’appuyer sur les critères suivants :
Dès lors les algorithmes peuvent utiliser les méthodes suivantes :
La liste ci-dessus n’est pas exhaustive, d’autres méthodes existent. Il est aussi possible de mélanger les méthodes (par exemple créer différentes files en fonction des degrés de priorités et appliquer un algorithme différent à chaque file…).
L’accès aux ressources est aussi un point à prendre en compte. Considérons la situation suivante :
Afin que l’exécution d’un processus se fasse de façon sécurisée, lorsqu’il accède à une ressource, celle-ci lui est allouée et indisponible pour les autre processus. Dans le cas présent, \(P_1\) et \(P_2\) ne demandent pas les mêmes ressources, ils peuvent être exécutés dans un ordre ou l’autre sans problème.
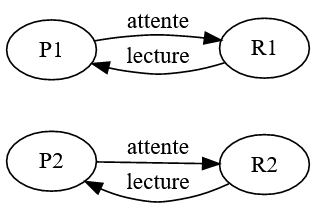
La situation devient problématique dans le cas suivant :
Cette situation s’appelle l’interblocage (deadlock en anglais).
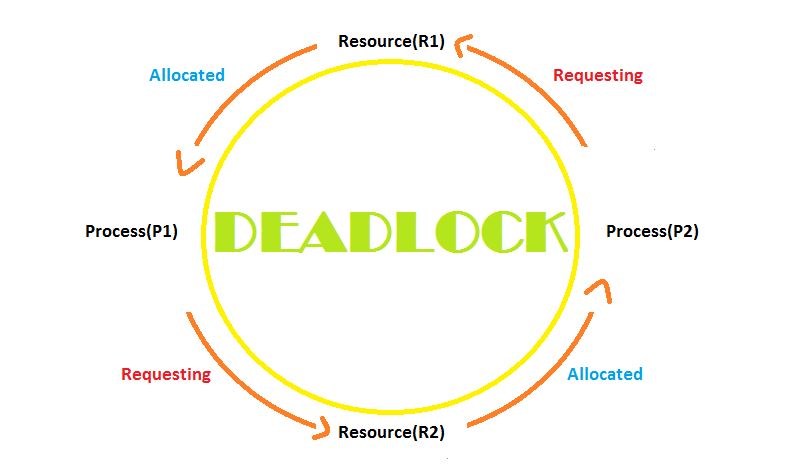
Une méthode pour éviter cette situation est de connaître à l’avance les ressources qui seront utilisées par les processus. On donnera la main à des processus sûrs, n’engendra pas d’interblocages. Il est aussi possible d’allouer les ressources en tenant compte du degré de priorité du processus demandeur.
Si la situation se présente tout de même le système d’exploitation peut par exemple terminer un des ou tous les processus impliqués dans l’interblocage ou reprendre la main sur la ressources bloquante et l’attribuer de façon autoritaire à l’un des processus jusqu’à ce que le blocage soit levé.